
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 수파자
- 큐
- 모각코
- 웹 기초
- 대학생
- CSS
- 연결 리스트
- FIFO
- 한국외대
- 대외활동
- 동적 배열
- 코딩좀알려주라
- 코딩
- HTML
- 리스트
- 한방향 연결 리스트
- 선형 자료 구조
- 한국대학생IT경영학회
- LIFO
- 알고리즘
- IT
- O(1)
- 스택
- 코뮤니티
- 서포터즈
- 프로그래밍
- 파이썬
- 자료구조
- 시간 복잡도
- 양방향 연결 리스트
- Today
- Total
대학생 쩡딱구리
2-3. 분할 분석과 성능 분석 본문
2-2. 동적 배열
2-1. 배열 1. 배열이란? 2020년 수능 시험에 548,734명이 지원했다고 한다. 이런 상황에서 54만명의 성적을 처리하려면 데이터를 어떻게 관리하는 것이 좋을까? 학생 개개인마다 변수를 선언해 자료�
jjeongttakgoori.tistory.com
동적 배열에서 이어진다.
1. 분할 분석

분할 분석(Amortization Analysis)이란 연산이 연속적으로 일어날 때 각 시점별로 연산을 따로 분석하지 않고 전체 연산을 함께 분석해 비용을 계산하는 방식이다. 위 그래프를 보도록 하자. 특정 시점의 연산량은 많지만 대부분의 시점에서 연산량이나 시간이 적다는 것을 알 수 있다. 이때 분할 분석을 사용하는 것이 효과적이다. 분할 분석은 단순히 분석방식이기보다 알고리즘의 설계 방식으로 이해하면 좋다.
2. 분할 분석 예시: Append
1) 2배 증가 방식

append의 경우 동적 배열이 1에서 시작해 2n의 크기로 계속 증가한다. 동적 배열의 크기를 2배씩 늘릴 경우 n번의 append 연산은 O(n)의 시간 복잡도를 가지며, 개별 append 연산에는 O(1)이 소요된다.
n번 append 시: O(n)
1번 append 시: O(1)
2) 고정 크기 증가 방식
동적 배열을 고정 크기로 늘리면 n번의 append 연산을 수행하는 데 O(n^2)가 소요된다.

이러한 상황에서 고정 증가량을 c, append 연산을 n번 하는 동안 배열의 크기가 c, 2c, 3c, ..., mc로 증가한다. m = [n/c]
전체 증가량: ∑mi=1 ci = c∑mi=1 i = cm(m+1)/2 >= c*n/2(n/2+1)/2 >= n^2/2c O(n^2)
3) 크기 감소 방식
크기 감소 시 메모리 사용량이 O(n)이 되게 보장하는 것이 중요하다. 사용량이 줄어들면 배열 크기를 줄여주어야 하는데, 증가와 감소가 너무 반복되지는 않게 해야 한다. 예를 들어 사용량이 1/4 미만이면 배열을 반으로 줄일 수 있다.
if 0 < self._n < self._capacity // 4:
self._resize(self._capcacity//2)4) Python 구현 분석
import sys
from time import time
try:
maxN = int(sys.argv[1])
except:
maxN = 10000000
from time import time # import the time function from the module
def compute_average(n):
"""Perform n appends to an empty list and return average time elapsed."""
data = []
start = time() # record the start time (in seconds)
for k in range(n):
data.append(None)
end = time() # record the end time (in seconds)
return (end - start / n) # compute the average per operation
n = 10
while n < maxN:
print('Average of {0:3f} for n {1}'.format(compute_average(n)*1000000, n))
n *= 10
5. 기본 연산 성능 분석
- data, data1, data2는 리스트이고 n, n1, n2는 각각의 길이
1) 리스트 기본 연산 성능
| Operation | Running Time | Comment |
| len(data) | O(1) | |
| data[j] | O(1) | |
| data.count(value) | O(n) | |
| data.index(value) | O(k+1) | k는 왼쪽부터 봤을 때 처음 value가 나타나는 인덱스 기준 (찾는 값이 없으면 k = n이 됨. 즉 O(n) |
| value in data | O(k+1) | |
| data1 == data2 (similarly !=, <, <=, >, >=) |
O(k+1) | k = min(n1, n2) 또는 값이 불일치하는 첫번째 인덱스 |
| data[j:k] | O(k-j+1) | |
| data1 + data2 | O(n1+n2) | |
| c*data | O(cn) |
2) 리스트 수정 연산 성능
| Operation | Running Time(amortized) | Comment |
| data[j] = val | O(1) | |
| data.append(value) | O(1) | |
| data.insert(k, value) | O(n-k+1) | 인덱스 k에 value를 넣기 |
| data.pop() | O(1) | |
| data.pop(k) del data[k] |
O(n-k) | 인덱스 k 꺼내기, 지우기 |
| data.remove(value) | O(n) | |
| data1.extend(data2) data1 += data2 |
O(n2) | |
| data.reverse() | O(n) | |
| data.sort() | O(nlogn) |
6. 문자열 생성
Q. 문서에서 알파벳만 추출하려 한다. 다음 코드의 성능은?
letters = '' # start with empty string
for c in document:
if c.isalpha():
letters += c # concantenate alphabetic characterAnswer: O(n^2)
- 문자열은 immutable하기 때문에 매번 letters += c마다 새로운 객체를 할당
1+2+3+...+(n-1)+n = n(n+1)/2
이 코드를 개선하는 방법으로 아래의 세 가지 방법이 있다.
1) 리스트로 문자를 append해서 새로운 문자열 생성
temp = [] # start with empty list
for c in document:
if c.isalpha():
temp.append(c) # append alphabetic character
letters = .join(temp) # compose overall result2) list comprehension으로 구현: 임시 리스트를 생성한다.
letters = ''.join([c for c in document if c.isalpha()]) 3) generator comprehension으로 구현: 임시 리스트를 생성하지 않는다.
letters = ''.join(c for c in document is c.isalpha())이 세 가지 개선방안의 성능은 모두 O(n)(amortized)이다!
6. 다차원 데이터의 표현
다차원 데이터는 리스트의 리스트로 표현할 수 있다. 예를 들어 아래의 데이터가 있을 때, data[1][3]과 같이 접근한다.
| 22 | 18 | 709 | 5 | 33 |
| 45 | 32 | 830 | 120 | 750 |
| 4 | 880 | 45 | 66 | 61 |
data = [[22, 18, 709, 5, 33], [45, 32, 830, 120, 750], [4, 880, 45, 66, 61]]
이러한 경우 아래와 같이 표시할 수도 있다. 예를 들어 [2, 4, 6]*2의 결과는 [2, 4, 6, 2, 4, 6]이므로 [0, 0, 0, ..., 0, 0]과 같이 c*r개의 0으로 구성된 리스트가 생성된다.
data = ([0]*c)*r

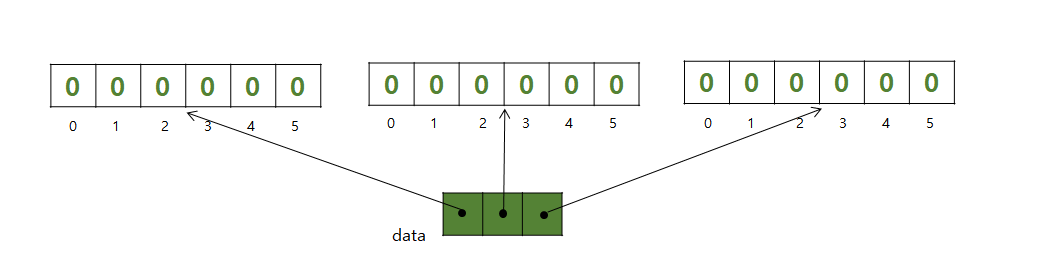
그렇다면, 아래와 같이 초기화하면 어떨까? 코드를 실행하면 그림과 같은 리스트가 생성될 것이다. 이때 한 가지 문제점이 있다. 만약 내가 data[2][0] = 100이라는 코드를 실행하면 data[0][0]과 data[1][0]도 같이 변경될 것이다.
data = [[0] * c]*r

그렇다면, 다음과 같이 초기화하면 어떨까? 두 번째 리스트가 각각 독립적으로 생성될 것이다.
data = [[0] * c for j in range(r)]
7. 동적 배열 구현: 과제
이전 게시글의 동적 배열 코드에서 reverse와 extend 함수를 추가한 버전이다. extend에서 resize를 2배로 늘리면 data1+data2가 2배보다 큰 경우 오류가 나게 되어 감점이 있는 코드이다. 수정한 버전으로 다시 올릴 예정.
import ctypes # provides low-level arrays
class DynamicArray:
"""A dynamic array class akin to a simplified Python list."""
def __init__(self):
"""Create an empty array."""
self._n = 0 # count actual elements
self._capacity = 1 # default array capacity
self._A = self._make_array(self._capacity) # low-level array
def __len__(self):
"""Return number of elements stored in the array."""
return self._n
def __getitem__(self, k):
"""Return element at index k."""
if not 0 <= k < self._n:
raise IndexError('invalid index')
return self._A[k] # retrieve from array
def append(self, obj):
"""Add object to end of the array."""
if self._n == self._capacity: # not enough room
self._resize(2 * self._capacity) # so double capacity
self._A[self._n] = obj
self._n += 1
def _resize(self, c): # nonpublic utitity
"""Resize internal array to capacity c."""
B = self._make_array(c) # new (bigger) array
for k in range(self._n): # for each existing value
B[k] = self._A[k]
self._A = B # use the bigger array
self._capacity = c
def _make_array(self, c): # nonpublic utitity
"""Return new array with capacity c."""
return (c * ctypes.py_object)() # see ctypes documentation
def insert(self, k, value):
"""Insert value at index k, shifting subsequent values rightward."""
# (for simplicity, we assume 0 <= k <= n in this verion)
if self._n == self._capacity: # not enough room
self._resize(2 * self._capacity) # so double capacity
for j in range(self._n, k, -1): # shift rightmost first
self._A[j] = self._A[j-1]
self._A[k] = value # store newest element
self._n += 1
def remove(self, value):
"""Remove first occurrence of value (or raise ValueError)."""
# note: we do not consider shrinking the dynamic array in this version
for k in range(self._n):
if self._A[k] == value: # found a match!
for j in range(k, self._n - 1): # shift others to fill gap
self._A[j] = self._A[j+1]
self._A[self._n - 1] = None # help garbage collection
self._n -= 1 # we have one less item
return # exit immediately
raise ValueError('value not found') # only reached if no match
def reverse(self):
for i in range(len(self) // 2):
temp = self._A[i]
self._A[i] = self._A[len(self) -1 -i]
self._A[len(self) -1 -i] = temp
return
def extend(self, data2):
if self._n == self._capacity: # not enough room
self._resize(2 * self._capacity) # so double capacity
for chunk in data2:
temp = []
self._A[self._n] = chunk
self._n += 1
return
def __repr__(self):
mylist = ", ".join(str(self._A[i]) for i in range(self._n))
return "[" + mylist + "]"
data1 = DynamicArray()
for i in range(10):
data1.append(i)
print("data1 : ", data1)
data2 = DynamicArray()
for i in range(10, 15, 1):
data2.append(i)
print("data2 : ", data2)
data1.extend(data2)
print("extended : ", data1)
data1.reverse()
print("reversed : ", data1)위의 코드를 실행하면 아래와 같은 결과가 출력된다.
data1 : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
data2 : [10, 11, 12, 13, 14]
extended : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
reversed : [14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]길고 긴 동적 배열이 이제 끝났다!
다음 게시글에선 새로운 자료구조 스택, 큐, 덱에 대해 다룬다.
'STUDIES > DATA STRUCTURE' 카테고리의 다른 글
| 3-2. 큐 (0) | 2020.10.17 |
|---|---|
| 3-1. 스택 (0) | 2020.10.17 |
| 2-2. 동적 배열 (0) | 2020.10.15 |
| 2-1. 배열 (0) | 2020.10.14 |
| 1-3. Big-O 표기법 (0) | 2020.10.14 |