
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 동적 배열
- 대학생
- 파이썬
- 한방향 연결 리스트
- IT
- 서포터즈
- LIFO
- 리스트
- 자료구조
- 코딩좀알려주라
- FIFO
- 모각코
- 수파자
- 스택
- O(1)
- CSS
- 한국대학생IT경영학회
- HTML
- 웹 기초
- 큐
- 코딩
- 코뮤니티
- 선형 자료 구조
- 알고리즘
- 한국외대
- 시간 복잡도
- 프로그래밍
- 양방향 연결 리스트
- 연결 리스트
- 대외활동
- Today
- Total
대학생 쩡딱구리
2-1. 배열 본문
1. 배열이란?
2020년 수능 시험에 548,734명이 지원했다고 한다.

이런 상황에서 54만명의 성적을 처리하려면 데이터를 어떻게 관리하는 것이 좋을까? 학생 개개인마다 변수를 선언해 자료를 관리하는 것은 불편할 것이다. 이런 문제점을 해결하는 자료구조 중 배열이 있다. 배열이란 동일한 타입의 데이터를 연속된 메모리 공간에 저장하여 하나의 변수로 표현하는 자료 구조를 말한다.
그렇다면 배열이 갖는 장점은 무엇일까? 배열은 각 요소의 길이가 같기 때문에 어떤 요소라도 바로 접근할 수 있다. 예를 들어, 배열에서 index i의 주소 = [배열의 시작 주소] + [요소의 크기] * i로, O(1)의 시간 복잡도를 가질 것이다. 또한, 배열에선 data[4]와 같은 추상화된 형태로 각 요소를 접근하게 만듦으로써 간단히 index만 표기하면 주소를 계산해 바로 이동할 수 있다. 즉, 배열은 순서 관계가 있는 각 요소에 빠르게 접근하기 위해 만든 자료 구조이다.
2. 파이썬 시퀀스 타입
0. 파이썬의 자료구조
지난 글에서 계속된다. 0. 알고리즘과 자료 구조 1. 알고리즘이란? "유튜브 알고리즘이 나를 꽤 괜찮은 곳으로 데리고 왔다." 2PM의 '우리 집' 유튜브 영상에 달린 베스트 댓글 중 하나다. 이 예��
jjeongttakgoori.tistory.com
예전 게시글의 내용을 다시 다루고 있다.
이전에 간단하게 다룬 시퀀스 타입의 자료구조인 리스트, 튜플, 스트링은 순서 정보가 중요하며 요소를 순서 관계에 따라 빠르게 접근하는 것이 중요한 자료구조이다. 따라서 시퀀스 타입의 자료구조인 이 셋은 배열 기반으로 설계되어 있다.
3. 배열의 종류
1) 컴팩트 배열(Compact Array)

배열 각 요소에 데이터를 직접 저장하며, 같은 타입의 데이터를 관리할 때 사용된다. 컴팩트 배열의 장점은 다음과 같다.
- 레퍼런스 배열에 비해 공간을 절약한다. (문자별로 유니코드 2 byte < 레퍼런스 배열: 레퍼런스 별로 8 byte)
- 연속 메모리에 있기 때문에 메모리 I/O 효율이 높다.
파이썬에서는 아래와 같이 컴팩트 배열을 만들 수 있다. 파이썬에선 C언어에서 지원하지 않는 데이터 타입을 지원하며, 사용자 정의형 array는 지원하지 않는다. 사용자 정의형 array의 경우 ctypes로 구현해야 한다.
prime = array(i, [2, 3, 5, 7, 11, 13, 17, 19]) # i = data type
2) 레퍼런스 배열(Reference Array)
레퍼런스 배열은 컴팩트 배열과 다르게 배열에서 참조하는 객체는 서로 다른 데이터 타입을 허용한다. 배열은 레퍼런스를 관리하며, 배열에서 동일한 타입의 객체를 다루고 있기는 하지만 서로 다른 타입의 객체 또는 가변 길이 데이터를 관리하기 위해서이다. 리스트와 튜플은 내부적으로 레퍼런스 배열을 사용한다.

a = ['Rene','Joseph', 'Janet', 'Jonas', 'Helen', 'Virgina', ...]그림에서의 레퍼런스 배열은 위와 같은 코드로 구현할 수 있다. 지금부터는 레퍼런스 배열의 연산에 대해 알아보자.
리스트 생성
레퍼런스 배열에서는 객체를 레퍼런스로 관리하기 때문에 다양한 타입을 하나의 배열로 관리할 수 있다. 이때 동적 타입을 지원한다.

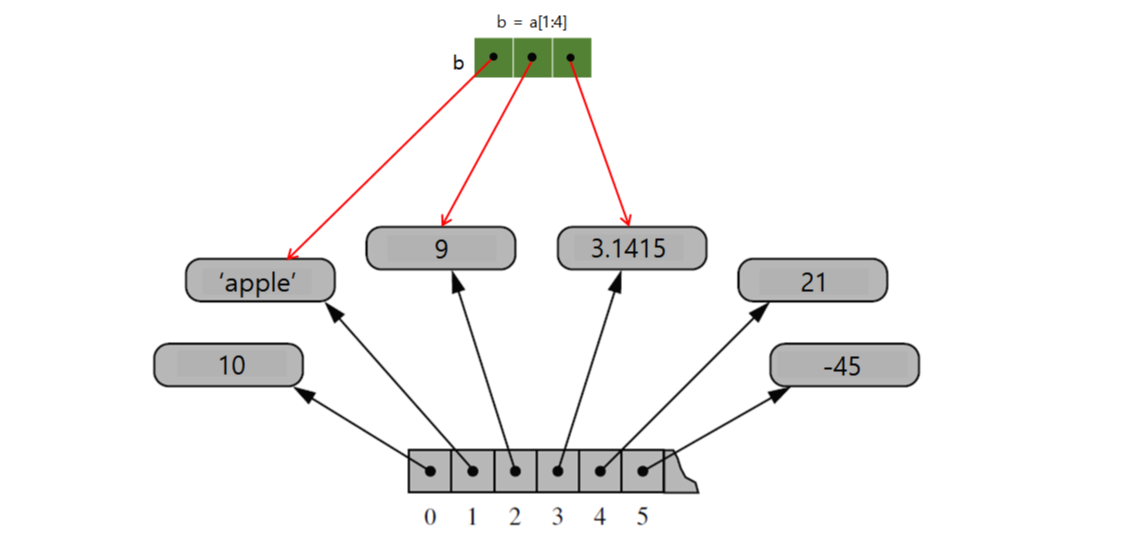
a = [10, 'apple', 7, 3.1415, 21, -45]
요소 값 변경
리스트는 참조하는 객체가 불변(immutable) 성질을 가지므로 요소 값이 바뀌면 새로운 객체를 생성하고 레퍼런스도 새로운 객체로 변경된다. 그림과 같은 상황의 경우 아래의 코드를 통해 요소값을 변경할 수 있다.

a[2] = a[2] + 2
레퍼런스 배열은 기존 리스트를 사용해 새로운 리스트를 생성하면 얕은 복사(Shallow Copy)를 한다.
슬라이싱
새로 생성된 리스트에서 레퍼런스만 복사하고 객체는 복사하지 않는 얕은 복사 방식을 취한다.
요소 값 변경
새로운 값을 배정하면 새로운 객체가 생성된다. 아래 그림에서 기존 객체를 참고하던 a[3]에는 영향이 없다.

심지어 같은 상수로 초기화할 떄도 모두 같은 객체를 참조하게 된다.
상수 초기화 + 리스트 생성
같은 객체의 레퍼런스로 배열이 초기화된다.

요소 값 변경

상수 초기화 + 리스트 생성
다른 리스트로 리스트를 확장할 때에도 얕은 복사가 이뤄진다.

다음 게시물에서는 동적 배열에 대해 다룬다.
'STUDIES > DATA STRUCTURE' 카테고리의 다른 글
| 2-3. 분할 분석과 성능 분석 (0) | 2020.10.16 |
|---|---|
| 2-2. 동적 배열 (0) | 2020.10.15 |
| 1-3. Big-O 표기법 (0) | 2020.10.14 |
| 1-2. 시간 복잡도 분석 (0) | 2020.10.13 |
| 1-1. 알고리즘 분석 (0) | 2020.10.13 |