
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 동적 배열
- 한국외대
- 선형 자료 구조
- CSS
- 알고리즘
- O(1)
- 코뮤니티
- 한방향 연결 리스트
- FIFO
- 대외활동
- 웹 기초
- HTML
- 모각코
- IT
- 코딩좀알려주라
- 스택
- 리스트
- 자료구조
- 큐
- 대학생
- 한국대학생IT경영학회
- 파이썬
- 양방향 연결 리스트
- LIFO
- 서포터즈
- 시간 복잡도
- 연결 리스트
- 프로그래밍
- 수파자
- 코딩
- Today
- Total
대학생 쩡딱구리
1-1. 알고리즘 분석 본문
0. 알고리즘과 자료 구조
1. 알고리즘이란? "유튜브 알고리즘이 나를 꽤 괜찮은 곳으로 데리고 왔다." 2PM의 '우리 집' 유튜브 영상에 달린 베스트 댓글 중 하나다. 이 예시와 같이 우리는 알게 모르게 알고리즘이라는 말
jjeongttakgoori.tistory.com
알고리즘이 무엇인지에 대해서는 위 글을 참고하면 좋을 것 같다.
1. 좋은 알고리즘이란?
정의하고자 하는 문제와 자료구조에 따라 알고리즘은 천차만별이다. 그렇다면 좋은 알고리즘이란 어떤 알고리즘일까?
좋은 알고리즘이란 1) 빠르게 실행되면서 2) 적은 공간을 사용하는 알고리즘이다. 두 가지가 알고리즘의 효율성을 결정하는데, 둘 중 우선순위를 고르자면 시간적인 요소가 더 중요하다.
2. 실험 분석
위에서 우리는 같은 내용의 알고리즘일 때 실행 시간이 짧은 알고리즘이 좋은 알고리즘이라는 것을 알게 되었다. 그렇다면 알고리즘의 실행 시간을 어떻게 분석할 수 있을까? 파이썬에서는 'time function'을 통해 시간을 측정할 수 있다.
from time import time
start_time = time()
Run algorithm
end_time = time()
elapsed = end_time - start_time알고리즘을 실행하기 전의 시간을 start_time, 알고리즘을 실행한 후의 시간을 end_time으로 선언했을 때,
'end_time - start_time = elapsed', 즉 알고리즘을 실행한 시간이다. time function은 "wall clock" 기준으로 시간을 측정하는 함수이기 때문에 CPU가 공유될 시 다른 프로세스가 실행되는 것에 영향을 받게 된다. 다른 프로세스에 영향을 받지 않도록 CPU time을 측정하고 싶다면 time function 대신 process_time을 import하면 되는데, 컴퓨터 시스템에 따라 CPU Clock 수가 다르므로 값이 바뀔 수 있다.
입력 크기가 달라질 때마다 실행 시간이 달라진다면 시각화(visualization)를 통한 트렌드 분석과 통계 분석(statistical analysis)을 통해 입력에 대한 실행 시간의 변화를 함수로 측정해야 한다. 이때 좋은 입력 데이터를 샘플링해야 하며, 실험을 많이 해야 의미있는 분석이 가능하다. 그러나 실험 분석에는 몇 가지 한계점이 따른다.
1) 어떤 알고리즘이 좋은지는 다양한 요소에 따라 달라질 수 있다
- 입력 데이터의 크기, 데이터의 상태(전처리 여부 등), 데이터 값의 제약 조건,
하드웨어 환경(컴퓨터 구조, 스토리지 종류 등), 소프트웨어 환경(OS, 미들웨어, 프레임워크 등)
2) 하드웨어, 소프트웨어 환경이 달라지면 알고리즘의 성능을 비교하기 어렵다.
3) 입력 데이터가 제한될 수밖에 없다.
4) 알고리즘의 구현되어야 분석이 가능하다!
이러한 한계점을 극복하기 위해 하드웨어, 소프트웨어에 관계없이 알고리즘을 비교할 수 있고 알고리즘을 구현하지 않아도 알고리즘이 기술된 코드나 문서를 통해 모든 입력을 고려하는 방식으로 알고리즘의 효율성을 분석하고자 아래와 같이 가정했다. 알고리즘의 실행 시간은 기본 연산 횟수에 비례한다.
-
알고리즘의 기본 연산을 정의 ex) 대입, 산술/논리/관계 연산, 제어문, 함수 호출 및 반환
-
명령어로 구성된 기본 연산은 단위 시간에 실행된다. 각 명령어는 CPU 시간 내에 실행이 된다.
-
모든 기본 연산은 수행 시간이 비슷하다.
3. 알고리즘 분석을 위한 주요 함수
1) 상수 함수(Constant Function)
: 입력 크기 n에 상관 없이 고정된 시간에 실행되며, 기본 연산을 수행하는 단계에서 유용, 기본 연산은 아래의 표에
f(n) = c
| 구분 | 연산 |
| 대입, 복사 연산 | A = B |
| 산술 연산 | +, -, *, /, % |
| 비교 연산 | >, >=, <, <=, ==, != |
| 논리 연산 | AND, OR, NOT |
| 비트문 | bit-AND, bit-OR, bit-NOT, bit-XOR, <<, >> |
| 비교문 | if, if else, if elseif ... else문 |
| 반복문 | for 문, while 문 |
| 함수 | 함수 정의, 함수 호출, return |
2) 로그 함수(Logarithm Function)
: 입력 데이터를 반 나누어 처리하는 경우의 연산 시간, 데이터를 이진(Binary) 형태로 처리할 경우의 저장 공간
f(n) = logbn (b>1, n>0, n != 1)
3) 선형 함수(Linear Function)
: n개의 입력에 대해 각 요소 별로 한 번에 처리하는 경우 (n개의 데이터를 읽는 데 n번의 연산 필요)
컴퓨터 메모리에 로딩되지 않은 n개의 데이터를 처리하는 알고리즘의 최고의 실행 시간
f(n) = n
4) nlogn 함수(n-log-n Function)
: 선형 함수보다 빠르게, 2차 함수보다 느리게 증가. 2차 함수 형태의 성능을 갖는 알고리즘 대비 선호
ex) 가장 빠른 정렬 알고리즘
f(n) = nlogn
5) 2차 함수(Quadratic Function)
: 알고리즘에 nested loop가 있을 때, nested loop에서 iteration 별로 inner loop의 연산 수가 증가하는 경우도 포함.
∑i=1ni= n(n+1) / 2
f(n) = n^2
6) 3차 함수(Cubic Function)
: 알고리즘에서 자주 나타나지는 않지만 종종 나타남.
f(n) = n^3
7) 다항 함수(Polynomial Function)
: 차수가 낮을수록 성능이 좋음.
f(n) = ∑di=0aini
8) 지수 함수(Exponential Function)
: Loop의 각 iteration마다 연산량이 일정한 비율로 증가
f(n) = a^n
∑i=0n ai = an+1 - 1 / a - 1
4. 함수 비교
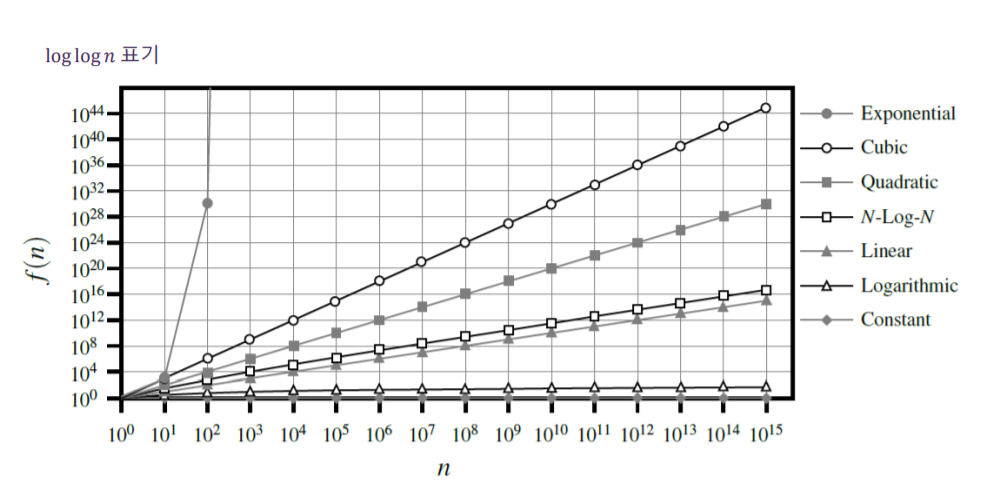
| 함수 종류 | 식 |
| 상수 함수 | f(n) = c |
| 로그 함수 | f(n) = logn |
| 선형 함수 | f(n) = nlogn |
| n-log-n 함수 | f(n) = n |
| 2차 함수 | f(n) = n^2 |
| 3차 함수 | f(n) = n^3 |
| 지수 함수 | f(n) = a^n |
다음 게시물에선 시간 복잡도와 Big -O 표기법에 대해 다룬다!
'STUDIES > DATA STRUCTURE' 카테고리의 다른 글
| 1-3. Big-O 표기법 (0) | 2020.10.14 |
|---|---|
| 1-2. 시간 복잡도 분석 (0) | 2020.10.13 |
| 0. 파이썬의 자료구조 (0) | 2020.10.10 |
| 0. 알고리즘과 자료 구조 (0) | 2020.10.10 |
| 자료구조 복습을 들어가며 (0) | 2020.10.10 |